

 GitHub
GitHub
Hang Su
I'm a research scientist in the Learning and Perception Research (LPR) team at NVIDIA Research. I completed my Ph.D. study in the Computer Vision Lab at UMass Amherst. Before that, I obtained my master's degree from Brown University and my bachelor's degree from Peking University.
I work in the areas of computer vision, graphics, and deep learning. In particular, I am interested in bringing together the strengths of 2D, 3D and 4D visual perception, as well as equipping AI agents with visual information from all modalities. Our work on 3D shape recognition won first place in the SHREC '16 Large-Scale 3D Shape Retrieval Contest, and I received the CVPR Best Paper Honorable Mention Award for our work on point cloud processing and the CVPR Best Paper Award Candidate for our work on monocular scene flow estimation.
Research Projects
L4P: Towards Unified Low-Level 4D Vision Perception

A unified framework for low-level 4D vision perception tasks, bridging 2D, 3D, and temporal understanding for autonomous navigation and robotics applications.
🏆 3DV 2026 Oral
Abhishek Badki*, Hang Su*, Bowen Wen, and Orazio Gallo, "L4P: Towards Unified Low-Level 4D Vision Perception", 3DV 2026.
Zero-shot Monocular Scene Flow Estimation in the Wild

A novel approach for zero-shot monocular scene flow estimation that works in challenging real-world scenarios without requiring training on specific datasets.
🏆 CVPR 2025 Oral, Best Paper Award Candidate
Yiqing Liang, Abhishek Badki*, Hang Su*, James Tompkin, and Orazio Gallo, "Zero-shot Monocular Scene Flow Estimation in the Wild", CVPR 2025.
HybridDepth: Robust Depth Fusion
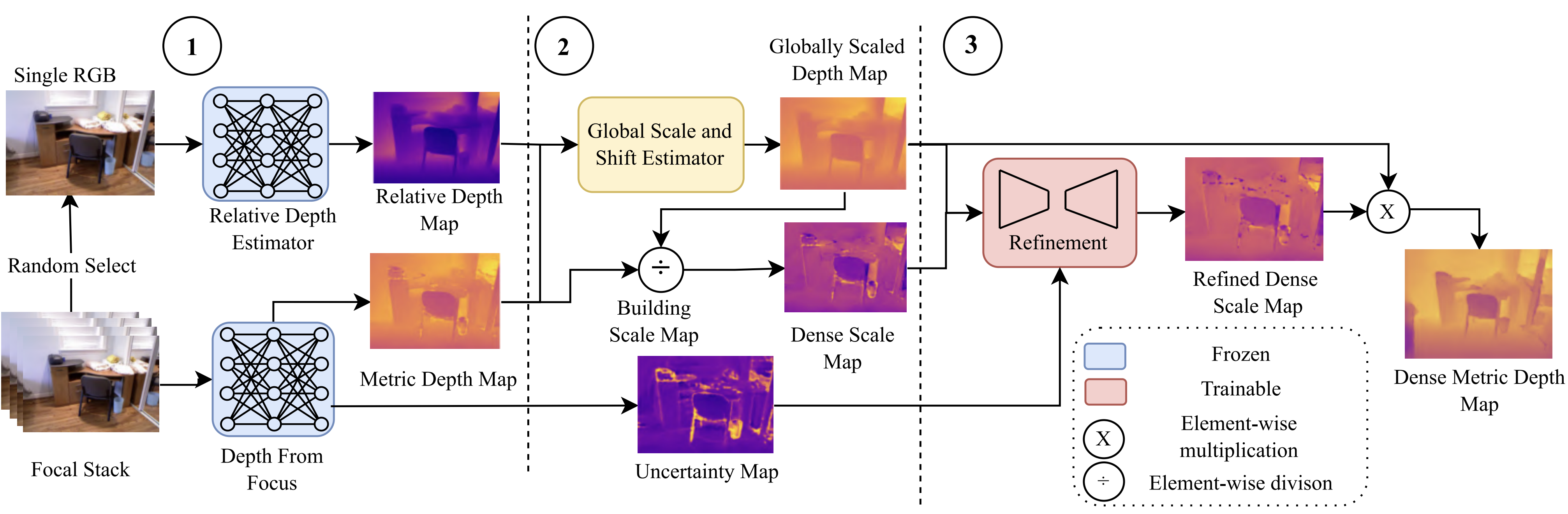
Depth estimation that combines depth from focus and single-image priors for robust metric depth fusion using focal stack images captured from a camera.
Ashkan Ganj, Hang Su, and Tian Guo, "HybridDepth: Robust Metric Depth Fusion by Leveraging Depth from Focus and Single-Image Priors", WACV 2025.
Ashkan Ganj, Hang Su, and Tian Guo, "Toward Robust Depth Fusion for Mobile AR With Depth from Focus and Single-Image Priors", ISMAR 2024.
Surround View Synthesis for In-Car Parking Visualization

Comprehensive surround-view visualizations to assist with in-car parking and navigation scenarios.
Abhishek Badki*, Hang Su*, Jan Kautz, and Orazio Gallo, "Surround View Synthesis for In-Car Parking Visualization", NVIDIA GTC 2024.
BlobGEN-3D: Compositional 3D-Consistent Freeview Image Generation
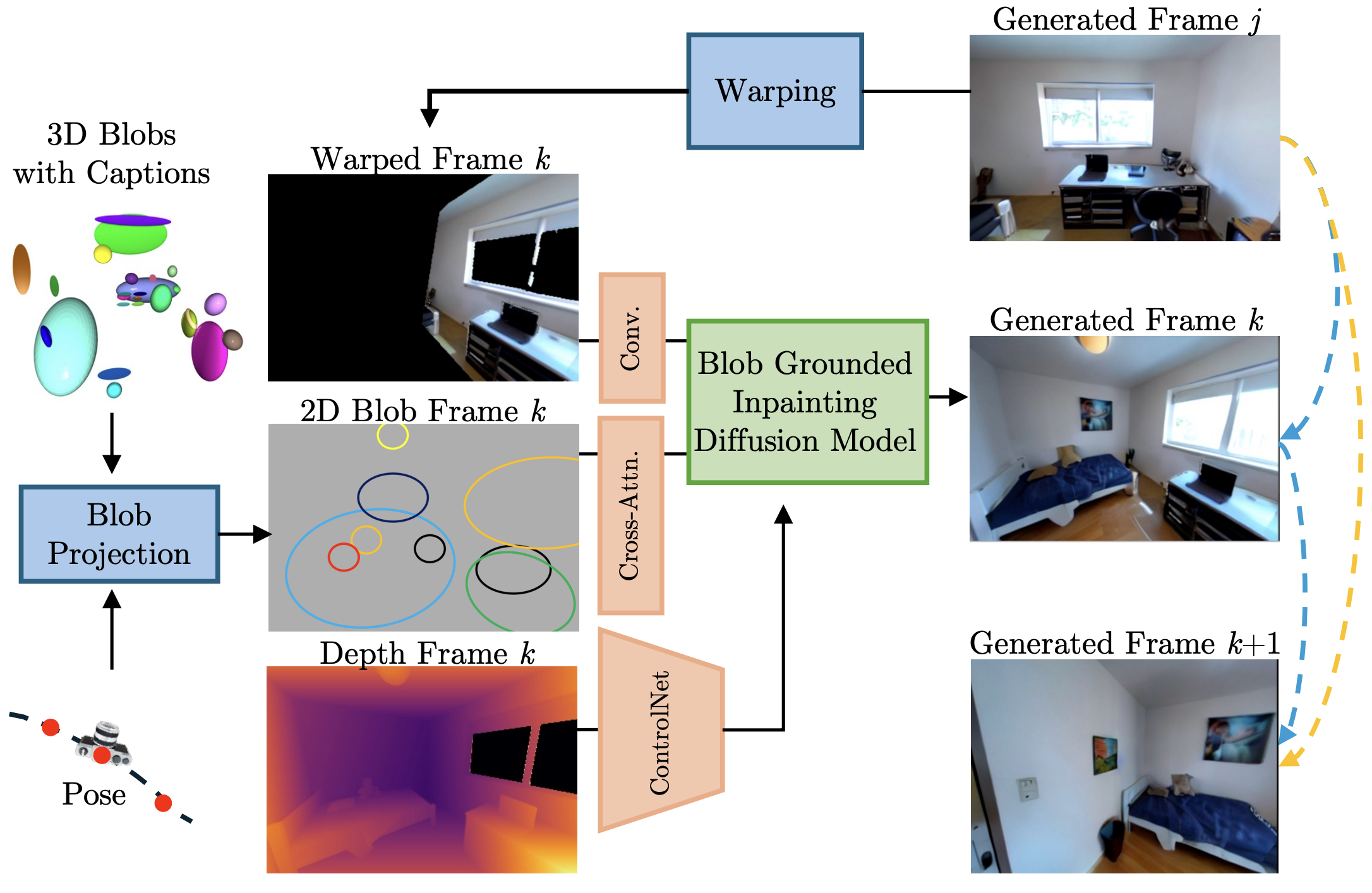
A novel framework for compositional 3D-consistent freeview image generation using 3D blobs, enabling high-quality novel view synthesis with improved geometric consistency.
Chao Liu, Weili Nie, Sifei Liu, Abhishek Badki, Hang Su, Morteza Mardani, Benjamin Eckart, and Arash Vahdat, "BlobGEN-3D: Compositional 3D-Consistent Freeview Image Generation with 3D Blobs", SIGGRAPH Asia 2024.
FoVA-Depth: Field-of-View Agnostic Depth Estimation
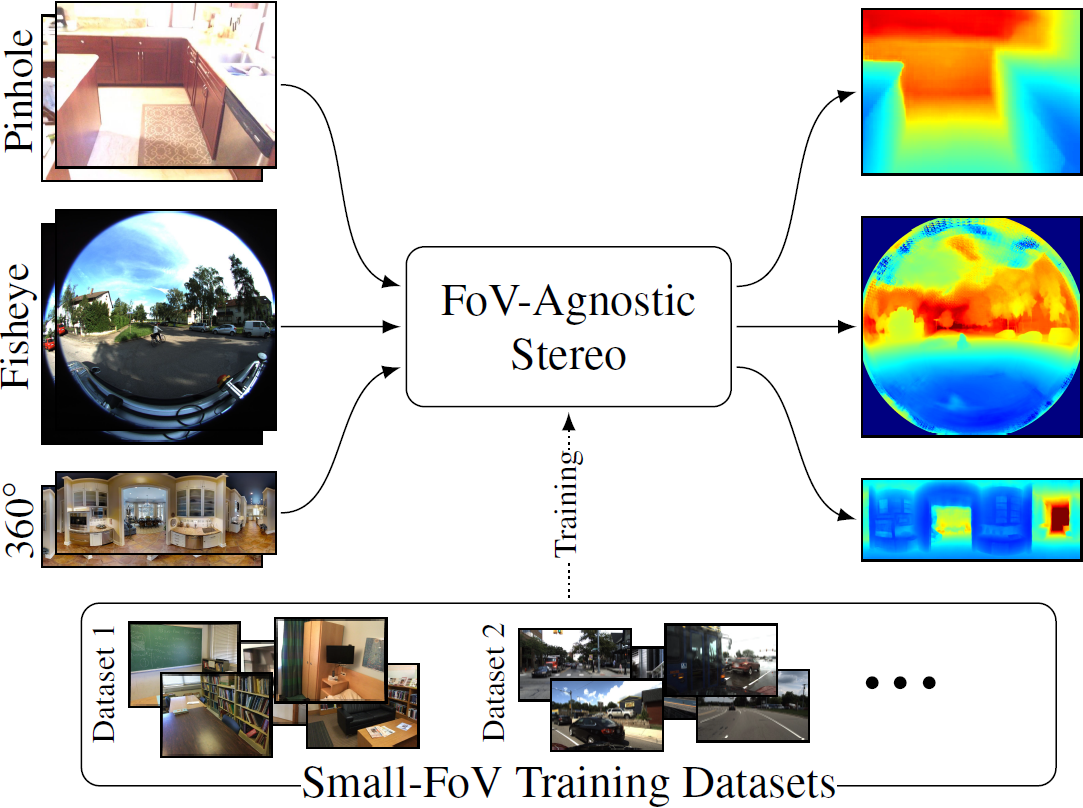
Field-of-view agnostic depth estimation method that enables robust cross-dataset generalization, addressing the challenge of varying camera parameters at inference time and across different datasets.
🏆 3DV 2024 Oral
Daniel Lichy, Hang Su, Abhishek Badki, Jan Kautz, and Orazio Gallo, "FoVA-Depth: Field-of-View Agnostic Depth Estimation for Cross-Dataset Generalization", 3DV 2024.
nvTorchCam: Camera-Agnostic Differentiable Geometric Vision
An open-source PyTorch library providing camera-agnostic differentiable geometric vision operations, enabling seamless integration of various camera models in deep learning pipelines.
Daniel Lichy, Hang Su, Abhishek Badki, Jan Kautz, and Orazio Gallo, "nvTorchCam: An Open-source Library for Camera-Agnostic Differentiable Geometric Vision", arXiv 2024.
Mobile AR Depth Estimation: Challenges & Prospects
A comprehensive study examining the challenges and future prospects of depth estimation for mobile augmented reality applications, addressing key technical and practical considerations.
Ashkan Ganj, Yiqin Zhao, Hang Su, and Tian Guo, "Mobile AR Depth Estimation: Challenges & Prospects", International Workshop on Mobile Computing Systems and Applications (HotMobile) 2024.
Pixel-Adaptive Convolution
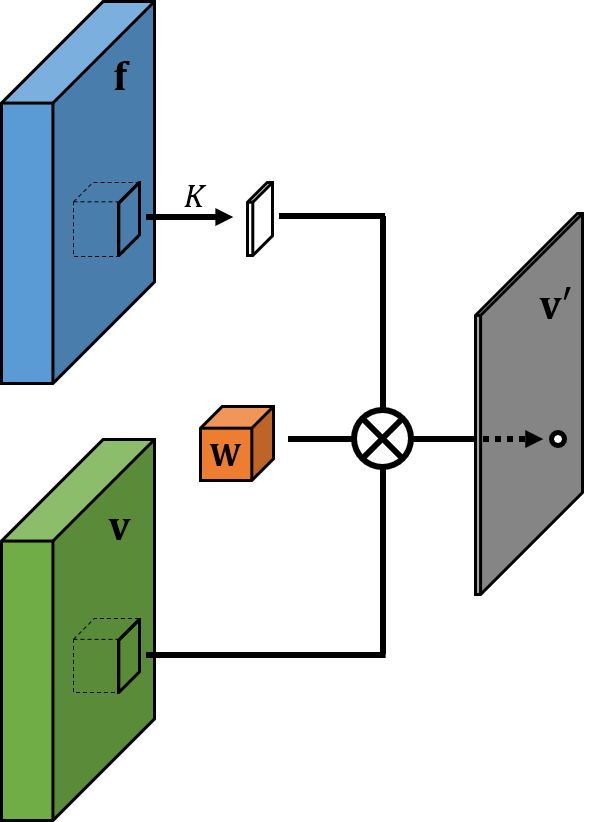
PAC is a content-adaptive operation that generalizes standard convolution and bilateral filters.
Hang Su, Varun Jampani, Deqing Sun, Orazio Gallo, Erik Learned-Miller, and Jan Kautz, "Pixel-Adaptive Convolutional Neural Networks", CVPR 2019.
Half&Half Benchmarks

Making intelligent decisions about unseen objects given only partial observations is a fundamental component of visual common sense. In this work, we formalize prediction tasks critical to visual common sense and introduce the Half&Half benchmarks to measure an agent's ability to perform these tasks.
Ashish Singh*, Hang Su*, SouYoung Jin, Huaizu Jiang, Chetan Manjesh, Geng Luo, Ziwei He, Li Hong, Erik G. Learned-Miller, and Rosemary Cowell, "Half&Half: New Tasks and Benchmarks for Studying Visual Common Sense", CVPR 2019 Workshop on Vision Meets Cognition.
SPLATNet: Sparse Lattice Networks for Point Cloud Processing

A fast and end-to-end trainable neural network that directly works on point clouds and can also do joint 2D-3D processing.
🏆 CVPR 2018 Oral, Best Paper Award Honorable Mention
🏆 NVAIL Pioneering Research Award
project page video pdf arXiv code
Hang Su, Varun Jampani, Deqing Sun, Subhransu Maji, Evangelos Kalogerakis, Ming-Hsuan Yang, and Jan Kautz, "SPLATNet: Sparse Lattice Networks for Point Cloud Processing", CVPR 2018.
End-to-end Face Detection and Cast Grouping in Movies Using Erdős–Rényi Clustering

An end-to-end system for detecting and clustering faces by identity in full-length movies.
🏆 ICCV 2017 Spotlight
SouYoung Jin, Hang Su, Chris Stauffer, and Erik Learned-Miller, "End-to-end face detection and cast grouping in movies using Erdős–Rényi clustering", ICCV 2017.
Multi-view CNN (MVCNN) for 3D Shape Recognition

A novel CNN architecture that combines information from multiple views of a 3D shape into a single and compact shape descriptor offering state-of-the-art performance in a range of recognition tasks.
🏆 Ranked #1 in SHREC'16 Large-Scale 3D Shape Retrieval Contest
project page video pdf arXiv code
Hang Su, Subhransu Maji, Evangelos Kalogerakis, and Erik Learned-Miller, "Multi-view Convolutional Neural Networks for 3D Shape Recognition", ICCV 2015.
M. Savva, et al., "SHREC’16 Track: Large-Scale 3D Shape Retrieval from ShapeNet Core55", Eurographics Workshop on 3D Object Retrieval, 2016.
The SUN Attribute Database: Beyond Categories for Deeper Scene Understanding
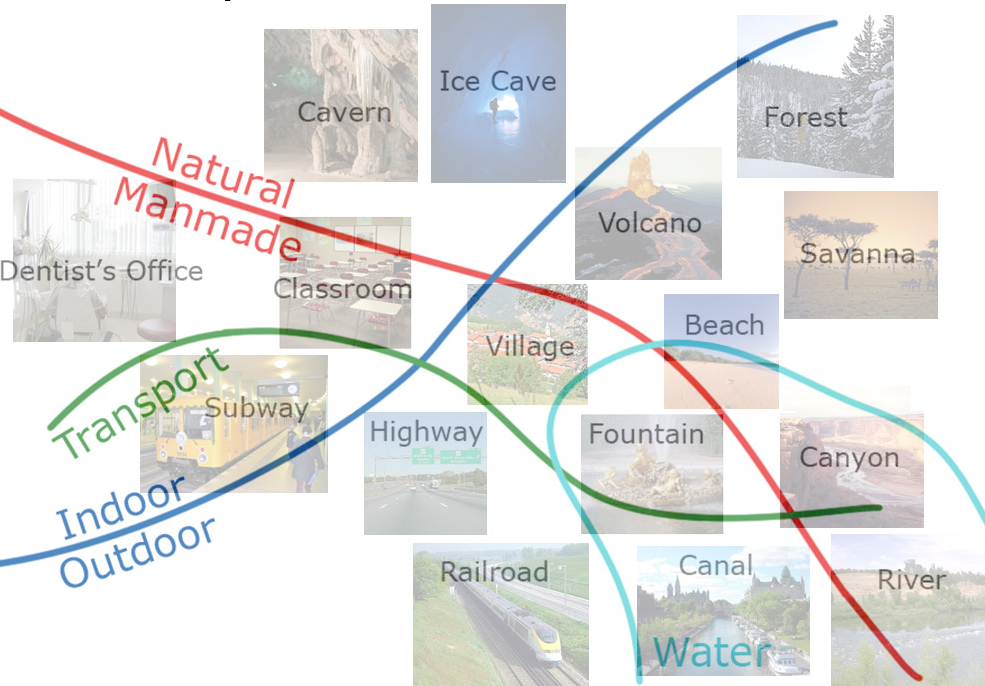
The first large-scale scene attribute database.
G. Patterson, C. Xu, H. Su, J. Hays, "The SUN Attribute Database: Beyond Categories for Deeper Scene Understanding", IJCV, May 2014.
Earlier Projects
Layered Global-Local (GLOC) Model for Image Parts Labelling with Occlusion 2014
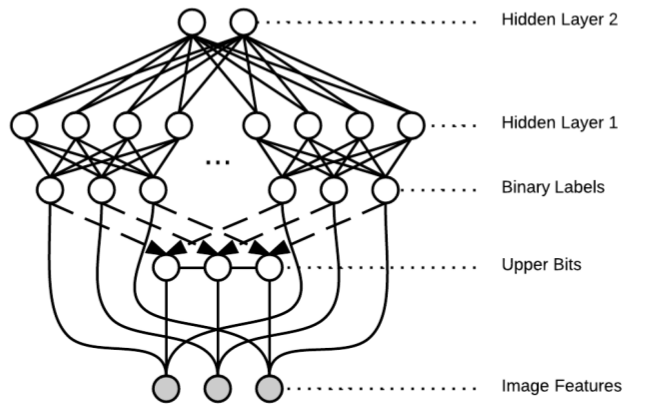
Learning and reasoning visual occlusions (e.g. on faces) using a deep graphical model. Co-advised by Professor Vangelis Kalogerakis and Professor Erik Learned-Miller.
We create an extension to LFW Part Labels dataset. It provides 7 part labels to 2,927 portrait photos.
data (lfw-parts-v2)
Face & Pose Detection Using Deformable Part-based Model 2012 Summer @eHarmony

In this project, I implemented in C++ a human face and body detection system based on the paper "Face detection, pose estimation and landmark localization in the wild" (X. Zhu and D. Ramanan, CVPR 2012). The implementation achieves 0.95 recall and 0.90 precision on eHarmony’s user profile photos.
Photo Quality Assessment on User Profile Photos 2012
The goal of this project is to automatically distinguish high quality professional photos from low quality snapshots.
We focus on assessing the quality of photos which contain faces (e.g. user profile photos). We propose several image features particularly useful for this task, e.g. skin smoothness, composition, bokeh. Experiments show that with small modifications they are also useful for assessing other types of photos.
Front Vehicle Detection Using Onboard Camera 2010-2011

Onboard vehicle detection plays a key role in collision prevention and autonomous driving. Camera-based detection techniques have been proven effective and economical, and show wide application prospect.
This project focuses on front vehicle detection using onboard cameras. Hypothesis generation based on shadows and hypothesis verification based on HOG features are combined to achieve a real-time system. We also introduce and integrate a passing vehicle detection component using optical flow, as well as road surface segmentation.
3D Modelling of Peking University Campus 2008

With almost 100 beautifully modeled 3D buildings on Peking University campus, our team won the top prize in 2008 Google International Model Your Campus Competition.